Hierarchical nowcasting of age stratified COVID-19 hospitalisations in Germany
Epinowcast Team
Source:vignettes/germany-age-stratified-nowcasting.Rmd
germany-age-stratified-nowcasting.RmdIn this vignette we explore using epinowcast to estimate COVID-19 hospitalisations by date of positive test in Germany stratified by age using several model specifications with different degrees of flexibility. We then evaluate the resulting nowcasts using visual checks, approximate leave-one-out (LOO) cross-validation using Pareto smoothed importance sampling, and out of sample scoring using the weighted interval score and other scoring measures for the single report date considered here. Before working through this vignette reading the model definition is advised (vignette("model-definition"))
Packages
We use the epinowcast package, data.table and purrr for data manipulation, ggplot2 for plotting, knitr to produce tables of output, loo to approximately evaluate out of sample performance and scoringutils to evaluate out of sample forecast performance.
Code
This vignette includes several models that take upwards of 30 minutes to fit to data on a moderately equipped laptop. To speed up model fitting if more CPUs are available set the number of threads used per chain to half the number of real cores available (here 6 as we are using 2 MCMC chains and have 12 real cores available). Note this may cause conflicts with other processes running on your computer and if this is an issue reduce the number of threads used.
Code
threads <- floor(min(max(1, parallel::detectCores() / 2), 6))
options(mc.cores = 2)Data
Nowcasting is effectively the estimation of reporting patterns for recently reported data. This requires data on these patterns for previous observations, which typically means the time series of data as reported on multiple consecutive days (in theory non-consecutive days could be used but this is not yet supported in epinowcast).
Here we use COVID-19 hospitalisations by date of positive test in Germany stratified by age group available from up to the 1st of September 2020 (with 40 days of data included prior to this) as an example of data available in real-time and hospitalisations by date of positive test available up to 20th of October to represent hospitalisations as finally reported. These data are sourced from the Robert Koch Institute via the Germany Nowcasting hub where they are deconvolved from weekly data and days with negative reported hospitalisations are adjusted.
We first filter out the data that would have been available on the 1st of September for the last 40 days.
Code
nat_germany_hosp <- epinowcast::germany_covid19_hosp[location == "DE"]
retro_nat_germany <- nat_germany_hosp |>
enw_filter_report_dates(latest_date = "2021-09-01") |>
enw_filter_reference_dates(include_days = 40)
retro_nat_germany
#> reference_date location age_group confirm report_date
#> <IDat> <fctr> <fctr> <int> <IDat>
#> 1: 2021-07-24 DE 00+ 31 2021-07-24
#> 2: 2021-07-25 DE 00+ 8 2021-07-25
#> 3: 2021-07-26 DE 00+ 9 2021-07-26
#> 4: 2021-07-27 DE 00+ 35 2021-07-27
#> 5: 2021-07-28 DE 00+ 51 2021-07-28
#> ---
#> 5736: 2021-07-24 DE 05-14 0 2021-09-01
#> 5737: 2021-07-24 DE 15-34 25 2021-09-01
#> 5738: 2021-07-24 DE 35-59 27 2021-09-01
#> 5739: 2021-07-24 DE 60-79 22 2021-09-01
#> 5740: 2021-07-24 DE 80+ 15 2021-09-01Similarly we then find the data that were available on the 20th of October for these dates, which will serve as the target “true” data.
Code
latest_nat_germany <- nat_germany_hosp |>
enw_filter_report_dates(latest_date = "2021-10-20") |>
enw_obs_at_delay(max_delay = 40) |>
enw_filter_reference_dates(latest_date = "2021-09-01", include_days = 40)Data preprocessing
epinowcast works by assuming data has been preprocessed into the reporting format it requires, coupled with meta data for both reference and report dates. enw_preprocess_data() can be used for this, although users can also use the internal functions to produce their own custom preprocessing steps. It is at this stage that arbitrary groupings of observations can be defined, which will then be propagated throughout all subsequent modelling steps. Here we have data stratified by age, and hence grouped by age group, but in principle this could be any grouping or combination of groups independent of the reference and report date models. We furthermore assume a maximum delay required to make the model identifiable. We set this to 40 days due to evidence of long reporting delays in this example data. However, note that in most cases the majority of right truncation occurs in the first few days and that increasing the maximum delay has a non-linear effect on run-time (i.e. a model with a maximum delay of 20 days will be much faster to fit than with 40 days). Note also that under the current formulation delays longer than the maximum are ignored so that the adjusted estimate is really for data reported after the maximum delay rather than for finally reported data.
Another key modelling choice we make at this stage is to model overall hospitalisations jointly with age groups rather than as an aggregation of age group estimates. This implicitly assumes that aggregated and non-aggregated data are not comparable (which may or may not be the case) but that the reporting process shares some of the same mechanisms. Another way to approach this would be to only model age stratified hospitalisations and then to aggregate the nowcast estimates into total counts after fitting the model.
Code
pobs <- enw_preprocess_data(retro_nat_germany, max_delay = 40, by = "age_group")
pobs
#> obs new_confirm latest
#> <list> <list> <list>
#> 1: <data.table[5740x9]> <data.table[5740x11]> <data.table[280x10]>
#> missing_reference reporting_triangle metareference
#> <list> <list> <list>
#> 1: <data.table[0x6]> <data.table[280x42]> <data.table[280x9]>
#> metareport metadelay max_delay time snapshots by
#> <list> <list> <num> <int> <int> <list>
#> 1: <data.table[553x12]> <data.table[40x5]> 40 40 280 age_group
#> groups max_date timestep
#> <int> <IDat> <char>
#> 1: 7 2021-09-01 dayModels
Here we explore a range of increasingly complex models using subject area knowledge and posterior predictive checks to motivate modelling choices.
Shared reporting delay distribution
We first explore a relatively simple model that assumes that reporting delays are fixed across age groups and time.
Note that here we use two chains each using 2 threads as a demonstration but in general using 4 chains is recommended. Also note that warm-up and sampling iterations have been set below default values to reduce compute requirements but this may not be sufficient for many real world use cases. Finally, note that here we have silenced fitting progress and potential warning messages but in general this should not be done.
Code
fit <- enw_fit_opts(
save_warmup = FALSE, output_loglik = TRUE, pp = TRUE,
chains = 2
, threads_per_chain = threads,
iter_sampling = 500, iter_warmup = 500,
show_messages = interactive(), refresh = ifelse(interactive(), 100, 0),
adapt_delta = 0.9, max_treedepth = 12
)
nowcast <- epinowcast(pobs,
fit = fit
)We first visualise the observations available to the model, the nowcast of final reported hospitalisations and the actual reported observations.
Code
plot(nowcast, latest_obs = latest_nat_germany) +
facet_wrap(vars(age_group), scales = "free_y")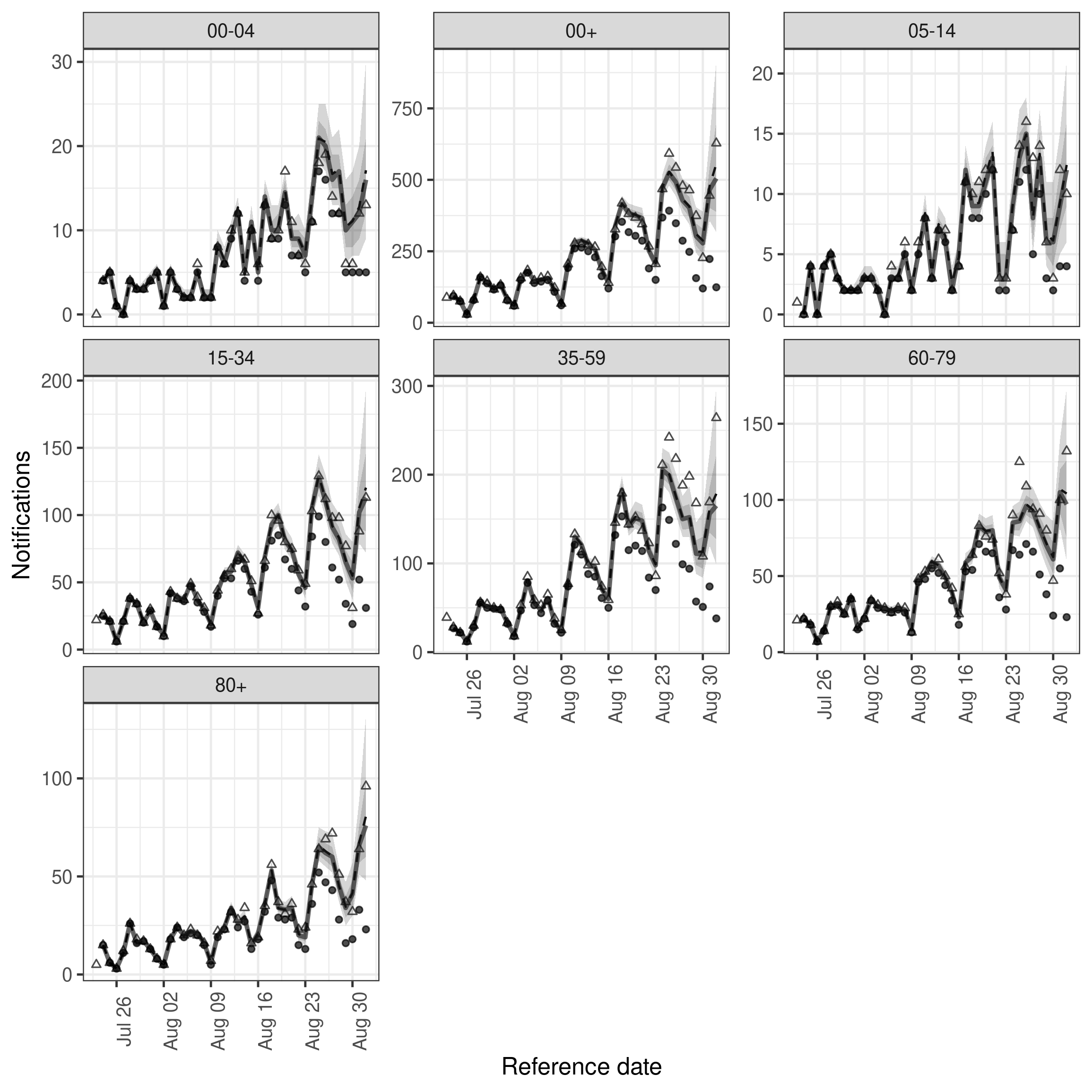
plot of chunk nowcast
Using the inflated posterior as a prior
To speed up model fitting we make use of posterior information from the previous model (with some inflation) for some parameters. Note that this is not a truly Bayesian approach and in some situations may be problematic.
See ?epinowcast for general guidance on inspecting and setting priors.
Code
priors <- summary(
nowcast,
type = "fit",
variables = c("refp_mean_int", "refp_sd_int", "sqrt_phi")
)
priors[, sd := sd * 1.5]
priors
#> variable mean median sd mad q5
#> <char> <num> <num> <num> <num> <num>
#> 1: refp_mean_int[1] 1.1318689 1.1196686 0.18657252 0.12073145 0.9469384
#> 2: refp_sd_int[1] 2.6065242 2.6016583 0.19868103 0.12495316 2.3955185
#> 3: sqrt_phi[1] 0.6415712 0.6405367 0.02783982 0.01837323 0.6110610
#> q20 q80 q95 rhat ess_bulk ess_tail
#> <num> <num> <num> <num> <num> <num>
#> 1: 1.025191 1.2311490 1.3463330 1.0024219 803.2077 746.8305
#> 2: 2.497948 2.7124564 2.8303578 1.0030131 780.4954 604.5020
#> 3: 0.626158 0.6569649 0.6719854 0.9997664 1475.4872 780.1094Reference day of the week effect
The underlying data we are trying to nowcast clearly has day of week periodicity. In our default model, a group specific random walk on the log of notified cases, this is not accounted for. Accounting for this, using a random effect on the day of the week is likely to improve nowcast performance and reduce the computation needed to fit the model. We can specify this using the enw_expectation() module and the formula interface as follows.
Code
expectation_module <- enw_expectation(
~ 0 + (1 | day_of_week) + (1 | day:.group), data = pobs
)
exp_nowcast <- epinowcast(pobs,
expectation = expectation_module,
fit = fit,
priors = priors
)We again visualise the nowcasts
Code
plot(exp_nowcast, latest_obs = latest_nat_germany) +
facet_wrap(vars(age_group), scales = "free_y")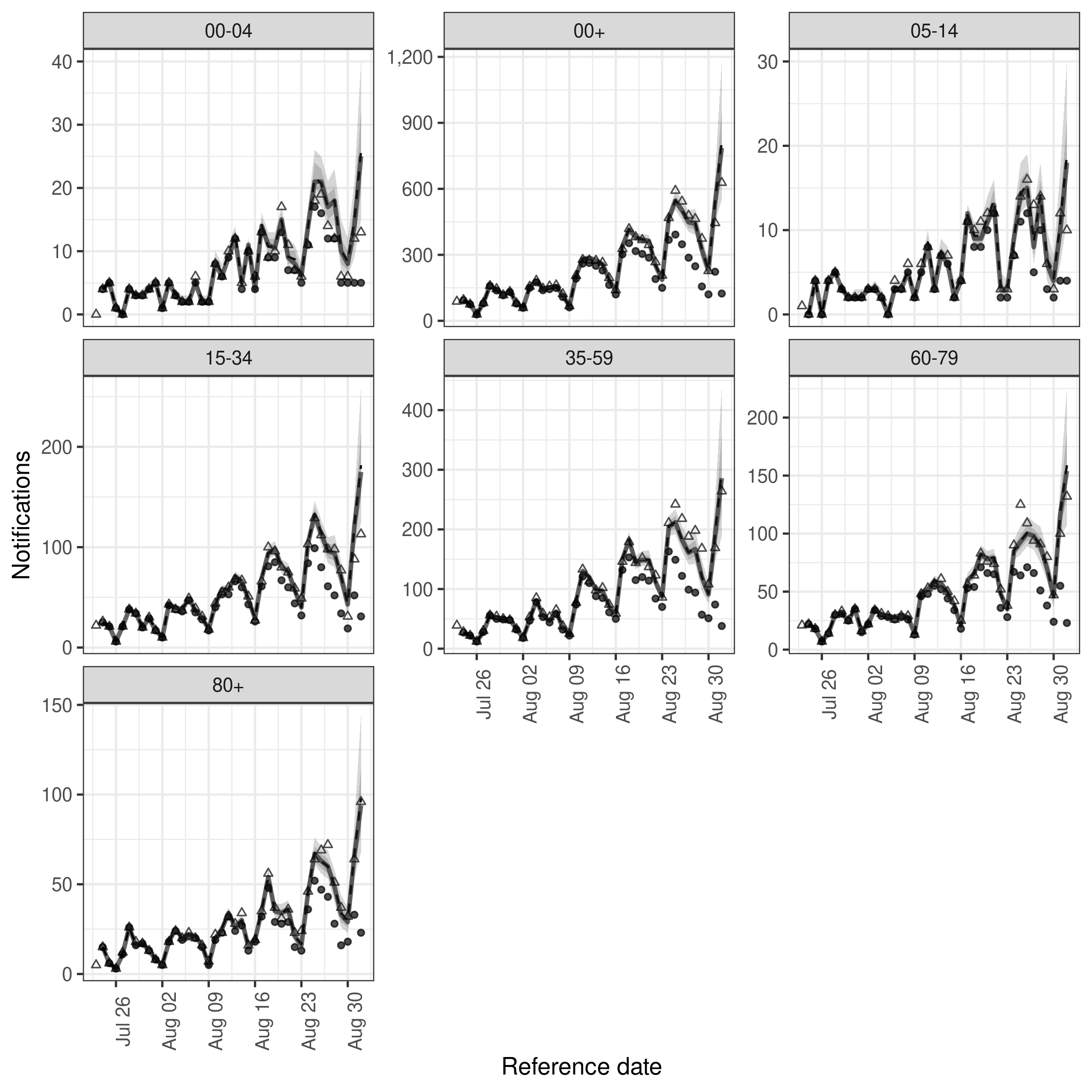
plot of chunk exp_nowcast
Posterior predictions
In order to identify areas where the current model is poorly reproducing the data we plot the posterior predictions against the data. This plot is faceted age group and reference data with the y axis showing the number of observations reported on a given day for a given reference day and the x axis showing the report date. We see fairly clearly oscillations in reported cases every 7 days which is expressed in the plot by oscillations in each facet that appear to move from left to right across facets. This indicates that some kind of week day adjustment may be needed.
Code
plot(exp_nowcast, type = "posterior") +
facet_wrap(vars(age_group, reference_date), scales = "free")
plot of chunk simple_pp
Reporting day of the week effect
As noted using the posterior predictions from the simple model fit above there appears to be a day of the week effect for reported observations. To adjust for this we introduce a random effect for day of the week by date of report using the following helper function which uses the metadata produced by enw_preprocess_data(). Note that epinowcast uses a sparse design matrix to reduce runtimes for some modules so the design matrix shows only unique rows with index containing the mapping to the full design matrix.
Code
report_module_dow <- enw_report(~ (1 | day_of_week), data = pobs)We now repeat the nowcasting step with the day of the week reporting model included.
Code
dow_nowcast <- epinowcast(pobs,
report = report_module_dow,
expectation = expectation_module,
fit = fit,
priors = priors
)Nowcast performance looks visually improved but there is notable variation across age groups with the 35-59 year old nowcast appearing quite poor (and as a result the aggregate nowcast also not showing great performance). We could also plot the posterior predictions for this model in the same way as for the previous model.
Code
plot(dow_nowcast, latest_obs = latest_nat_germany) +
facet_wrap(vars(age_group), scales = "free_y")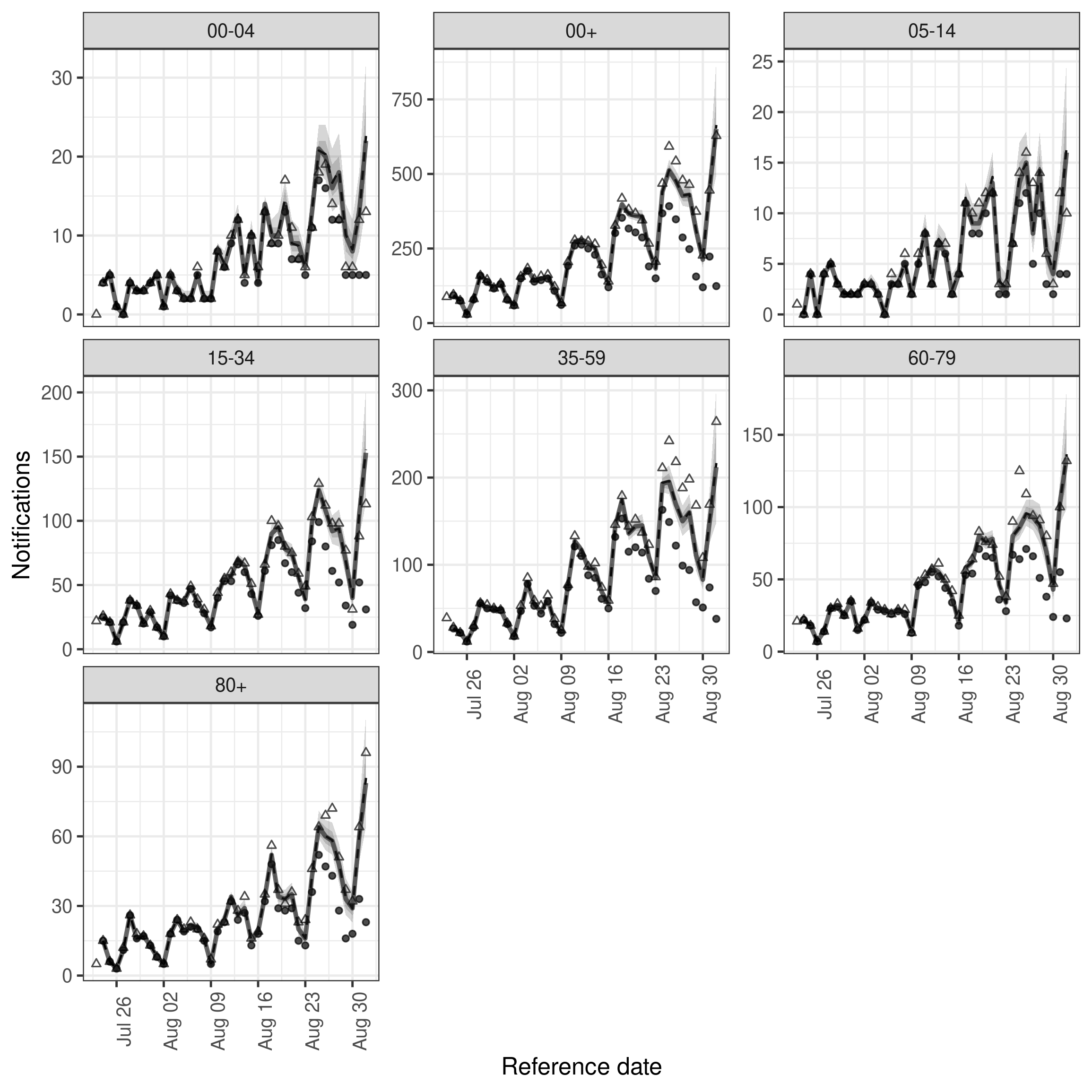
plot of chunk dow_nowcast
Age group variation
It is quite likely that there is some variation in the reporting delay by age and that this may be driving the variation in nowcast performance noted for the last model. Here we model this using a random effect for 5 year age group (as these were the groups supplied in the data).
Code
reference_module_age <- enw_reference(~ 1 + (1 | age_group), data = pobs)We again nowcast this time using both the age adjusted reference date model and the day of the week adjusted report date model.
Code
age_nowcast <- epinowcast(pobs,
reference = reference_module_age,
report = report_module_dow,
expectation = expectation_module,
fit = fit,
priors = priors
)Fit looks slightly better with this adjustment though uncertainty has also increased for all age groups and performance for the final day of data may have reduced compared to the first model.
Code
plot(age_nowcast, latest_obs = latest_nat_germany) +
facet_wrap(vars(age_group), scales = "free_y")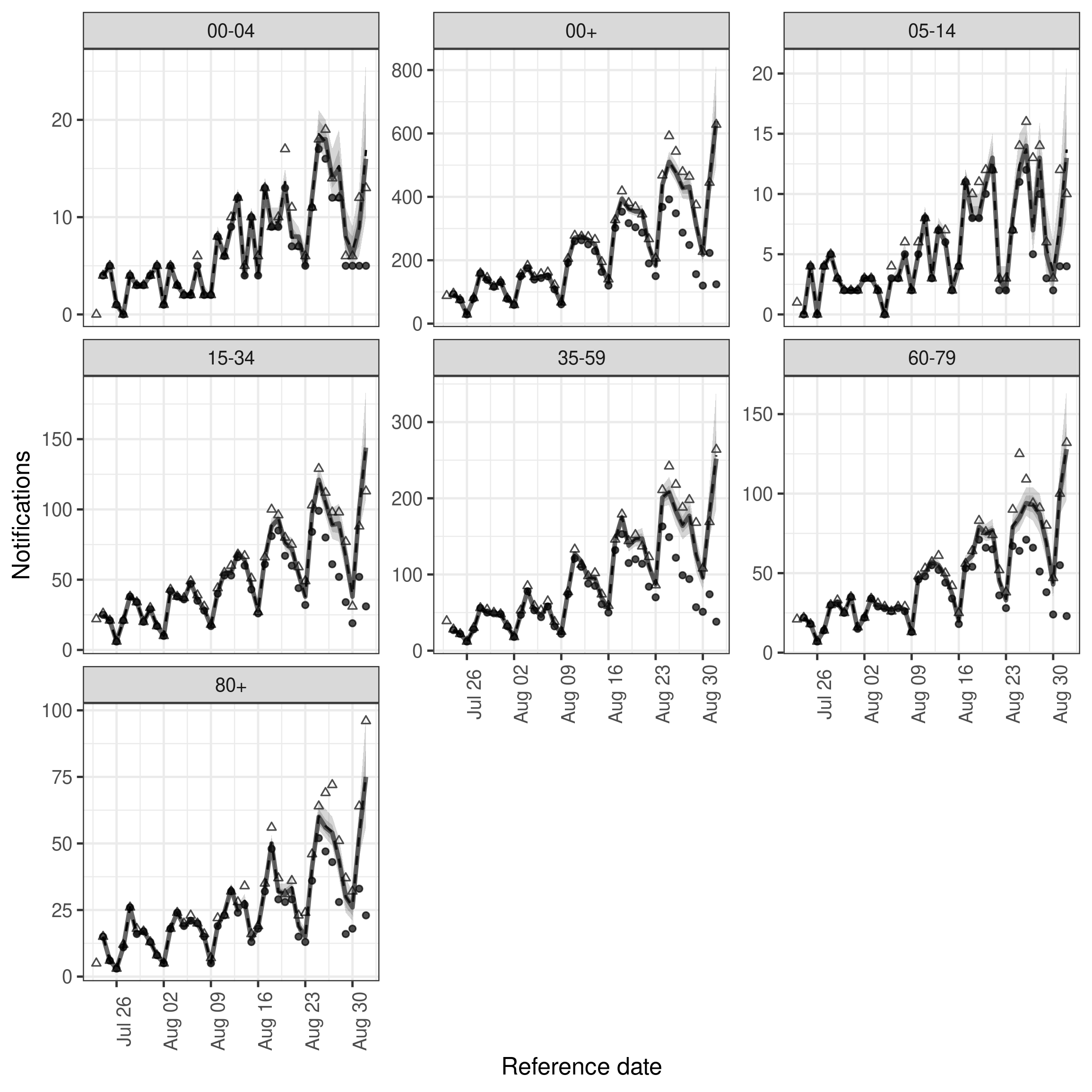
plot of chunk age_nowcast
Variation based on reference date
It could be the case that reporting delays change over time as well as across age groups. One way of modelling this is to assume piecewise constant variation over time modelled with a first order weekly random walk. An attractive property of this approach is that it limits the number of report date distributions that need to be evaluated in the model to the number of weeks of data and as this is an expensive computational step using this approach to introducing a time-varying parameter limits the additional computational overhead.
Code
reference_module_age_week <- enw_reference(
~ 1 + (1 | age_group) + rw(week), data = pobs
)As before we fit the nowcasting model,
Code
week_nowcast <- epinowcast(pobs,
reference = reference_module_age_week,
report = report_module_dow,
expectation = expectation_module,
fit = fit,
priors = priors
)In comparison to the previous model it looks like the introduction of variation over time has introduce a slight improvement in capturing hospitalisations in some age groups.
Code
plot(week_nowcast, latest_obs = latest_nat_germany) +
facet_wrap(vars(age_group), scales = "free_y")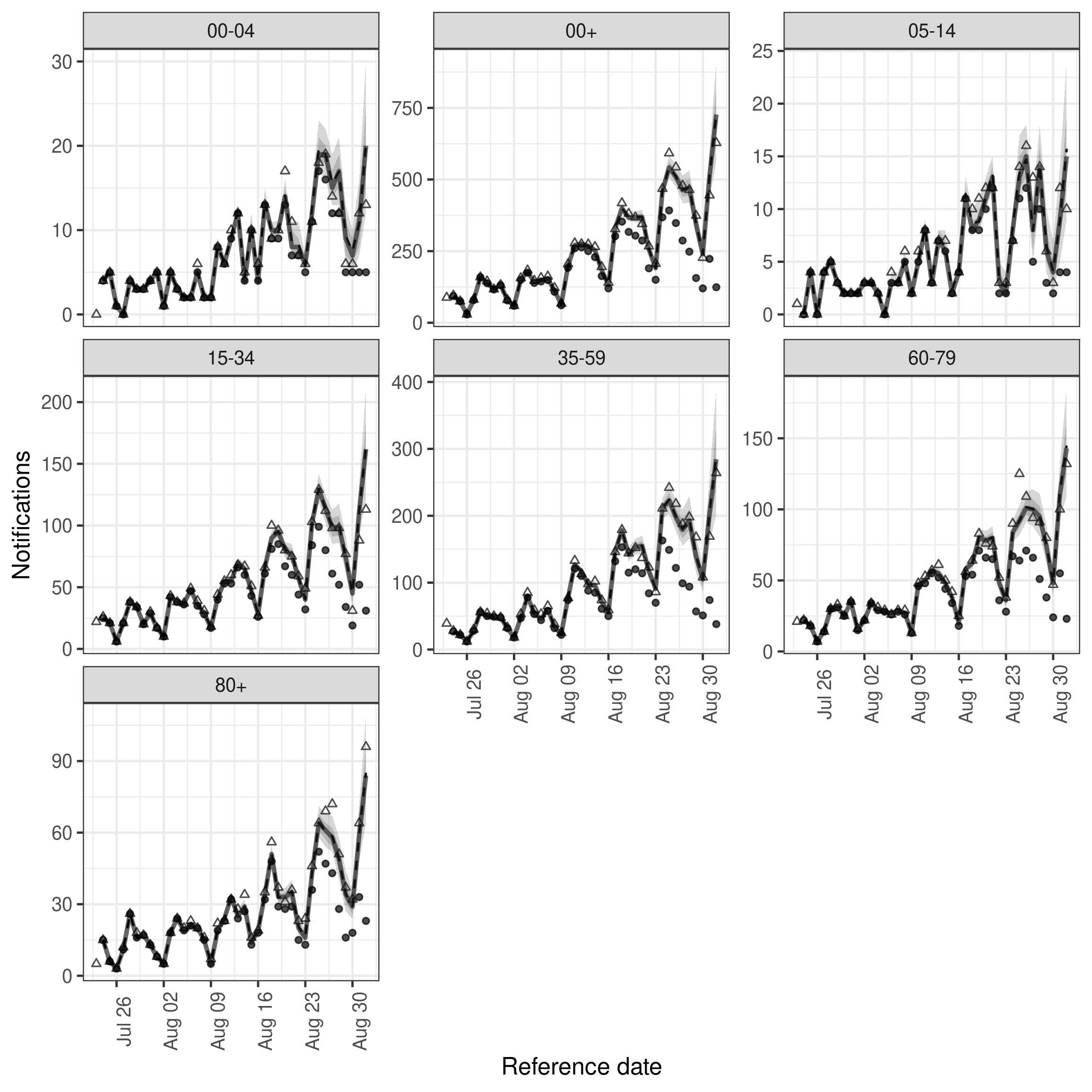
plot of chunk week_nowcast
Variation based on reference date stratified by age
As a final hierarchical model it makes sense to explore whether there is evidence that reporting delays vary by week and age group jointly. In this scenario the assumption is that delays may evolve differently over time for each age group but reporting effects and measurement error are still shared across data sets.
Code
reference_module_week_by_age <- enw_reference(
~ 1 + (1 | age_group) + rw(week, by = age_group), data = pobs
)We can now fit this model as before.
Code
age_week_nowcast <- epinowcast(pobs,
reference = reference_module_week_by_age,
report = report_module_dow,
expectation = expectation_module,
fit = fit,
priors = priors
)In comparison to the previous model it looks like the introduction of variation over time has introduce a slight improvement in capturing hospitalisations in some age groups.
Code
plot(age_week_nowcast, latest_obs = latest_nat_germany) +
facet_wrap(vars(age_group), scales = "free_y")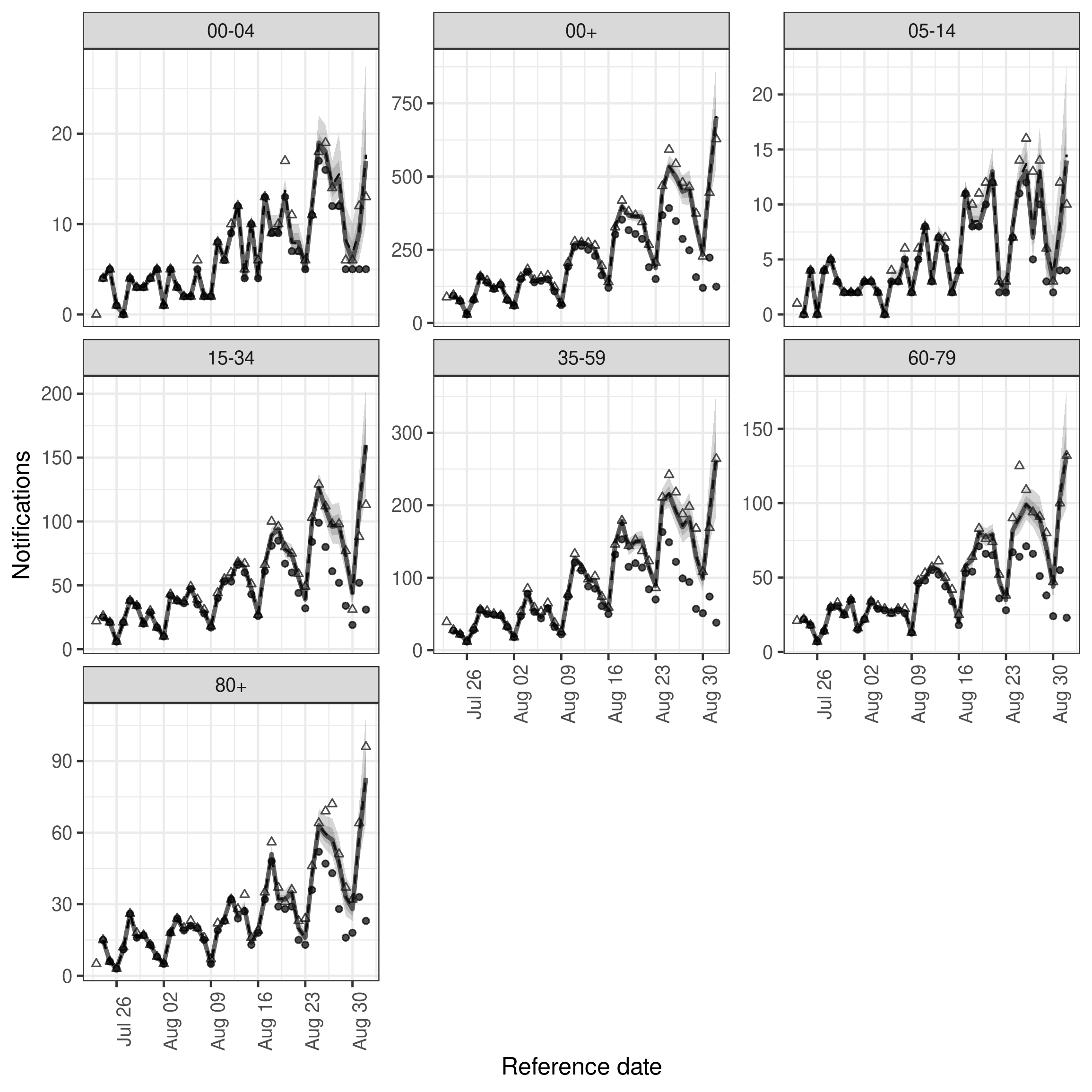
plot of chunk age_week_nowcast
Independent models for each age group.
The obvious question to ask at this stage is if using a model that jointly fits to all age groups at once is actually beneficial. Here we explore this by fitting the same model as previously (a day of week effect for report date and a random walk on the week of the reference date stratified by age) to each age group independently.
We could define this model with a single call to epinowcast but fitting each dataset independently but in a joint setting would likely lead to long fit times for no real benefit. Instead here we write a small helper function to preprocess our input data, define report and reference date models and then run a nowcast.
Code
independent_epinowcast <- function(obs, max_delay = 40, ...) {
pobs_ind <- enw_preprocess_data(obs, max_delay = max_delay)
nowcast <- epinowcast(
data = pobs_ind,
reference = enw_reference(~ rw(week), data = pobs_ind),
report = enw_report(~ (1 | day_of_week), data = pobs_ind),
expectation = enw_expectation(
~ 0 + (1 | day_of_week) + (1 | day), data = pobs_ind
),
...
)
return(nowcast)
}We can now use this wrapper function on the data available for each age group, summarise the resulting nowcast, and then join these into a single data.frame.
Code
options(mc.cores = 2)
independent_nowcast <- map(
split(retro_nat_germany, by = "age_group"),
independent_epinowcast,
fit = enw_fit_opts(
save_warmup = FALSE, output_loglik = TRUE, pp = TRUE,
chains = 2, threads_per_chain = threads,
iter_sampling = 500, iter_warmup = 500,
show_messages = FALSE, refresh = 0,
adapt_delta = 0.95, max_treedepth = 12
),
priors = priors
)
independent_nowcast_summary <- map_dfr(
independent_nowcast,
summary,
probs = c(0.025, 0.05, seq(0.1, 0.9, by = 0.1), 0.95, 0.975)
)As we now have the summarised nowcasts rather than an object of class epinowcast we need to make use of the underlying plot function ourselves. Doing so we see that performance is generally quite good across the board though the width of credible intervals has also increased. Importantly the 35-59 year old age group is being captured at least as well as in the hierarchical models with only minor reductions in performance in other age groups. This suggests that for this dataset and nowcast date there may be relatively little benefit to jointly modelling age groups.
Code
enw_plot_nowcast_quantiles(
independent_nowcast_summary, latest_obs = latest_nat_germany
) +
facet_wrap(vars(age_group), scales = "free_y")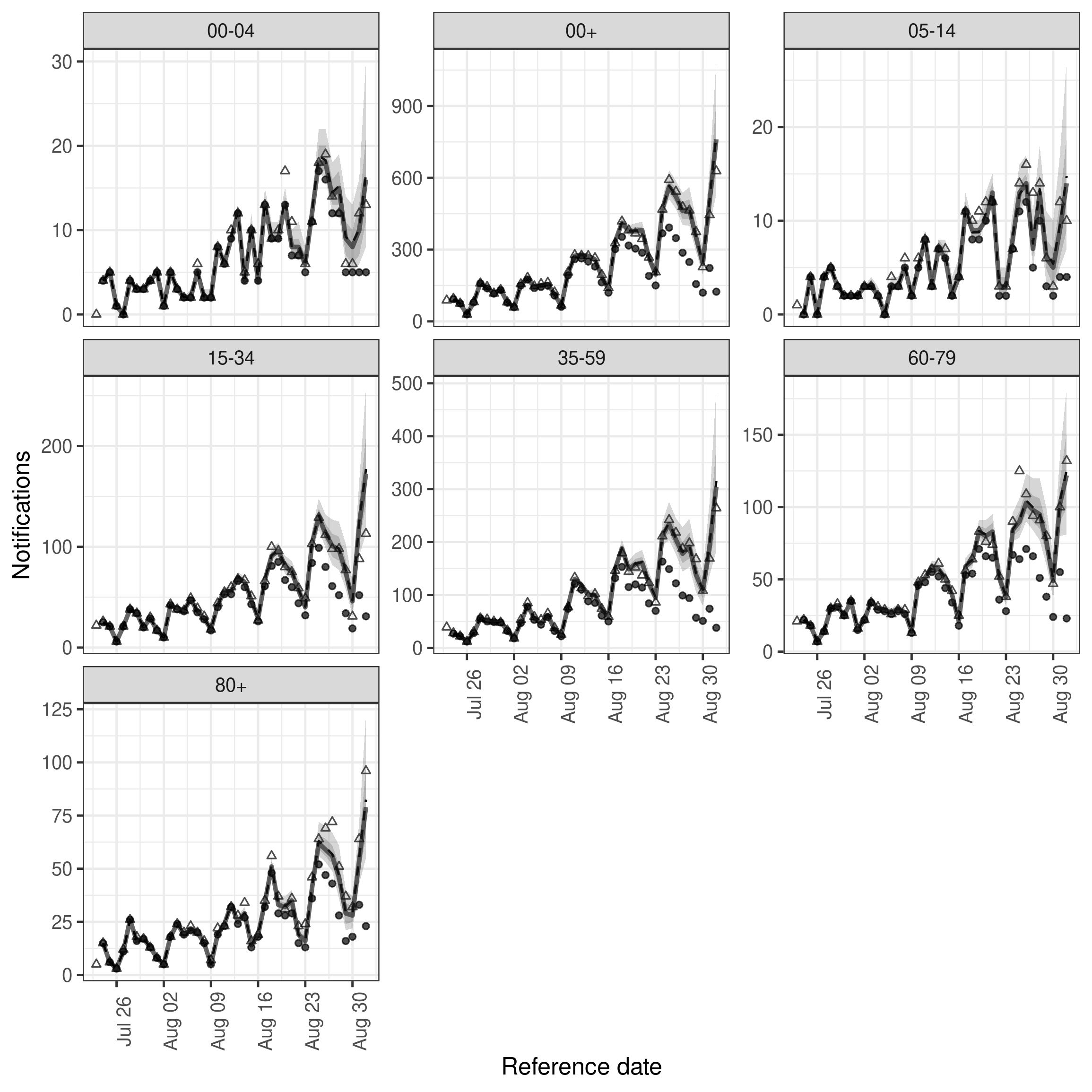
plot of chunk ind_nowcast
Alternative models
In all the models defined above we have assumed that the delay distribution, aside from report date effects, is parametric and has a lognormal distribution. Both of these assumptions may be less than optimal. Alternatives include assuming a different distributional form (such as the gamma distribution which is also supported by epinowcast) or assuming that the report delay is fully non-parametric which is not yet supported but will be in future package versions.
There are any number of additional models we could explore within the framework supported by epinowcast as well as a large number of alternative parameterisations that are not yet supported. For example, we could explore models with more complex reporting day effects, including holidays (supported in epinowcast either as a separate effect or by assuming they have the same reporting hazard as Sundays) and variation over time which would represent reporting delays changing independently of reference date (this would be similar to the time varying model we defined above but with this effect occurring in the report date model rather than in the reference date model). These choices are data dependent and domain knowledge needs to be used to assess the likely mechanisms.
If interested in expanding the functionality of the underlying model to address some of these issues note that epinowcast allows users to pass in their own models meaning that alternative parameterisations may be easily tested within the package infrastructure. Once this testing has been done alterations that increase the flexibility of the package model and improves its defaults are very welcome as pull requests.
Evaluation
As we have only nowcast a single date, and we visualised performance as we went, this evaluation is anything but complete or rigorous but we can give some examples of how we might evaluate performance more generally and potentially draw some useful initial conclusions.
We first list all models (including the simplest case) and give them informative names,
Code
nowcasts <- list(
"Reference: Fixed, Report: Fixed" = exp_nowcast,
"Reference: Fixed, Report: Day of week" = dow_nowcast,
"Reference: Age, Report: Day of week" = age_nowcast,
"Reference: Age and week, Report: Day of week" = week_nowcast,
"Reference: Age and week by age, Report: Day of week" = age_week_nowcast
)and then summarise the nowcast posterior for each model and join into a tidy data.frame to make further analysis easier.
Code
summarised_nowcasts <- map(
nowcasts, summary,
probs = c(0.025, 0.05, seq(0.1, 0.9, by = 0.1), 0.95, 0.975)
)
summarised_nowcasts$`Independent by age, Reference: Week, Report: Day of week` <- independent_nowcast_summary # nolint
summarised_nowcasts <- rbindlist(summarised_nowcasts, idcol = "model",
use.names = TRUE)
summarised_nowcasts[, `:=`(
model = factor(
model,
levels = c("Reference: Fixed, Report: Fixed",
"Reference: Fixed, Report: Day of week",
"Reference: Age, Report: Day of week",
"Reference: Age and week, Report: Day of week",
"Reference: Age and week by age, Report: Day of week",
"Independent by age, Reference: Week, Report: Day of week")),
age_group = factor(
age_group,
levels = c("00+", "00-04", "05-14", "15-34", "35-59", "60-79", "80+"))
)]This allows us to plot nowcasts for each model and age group compared to the latest data. Looking at the plot shows some small differences across models with uncertainty generally decreasing as model complexity increases. Some age groups are clearly better nowcast than others with the 35-59 year old age group in particular having poor nowcast coverage.
Code
enw_plot_nowcast_quantiles(
summarised_nowcasts, latest_obs = latest_nat_germany
) +
facet_grid(vars(age_group), vars(model), scales = "free_y")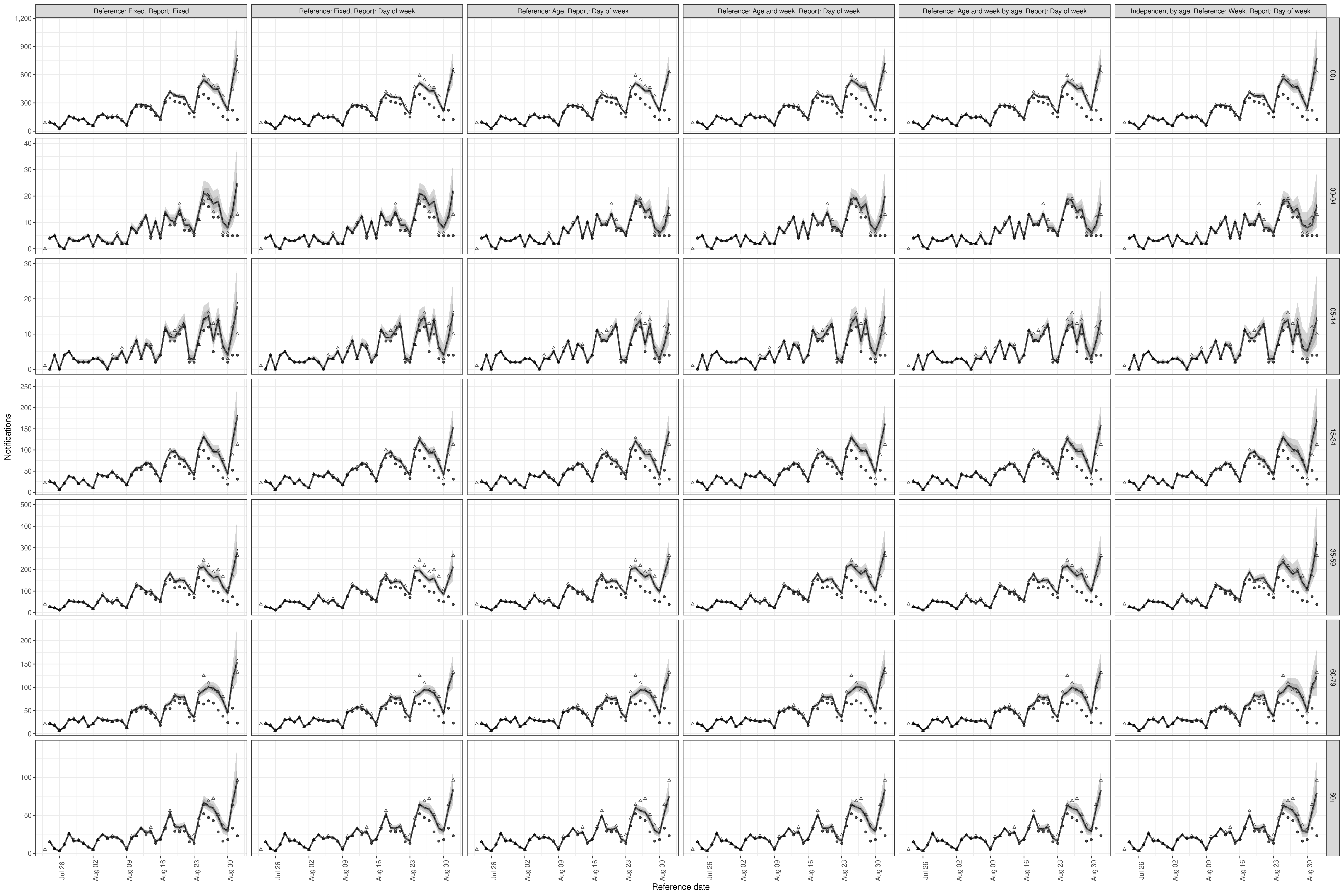
plot of chunk unnamed-chunk-18
As a crude measure of general out of sample performance we can use the leave one out information criterion as supplied by the loo package though note this is not typically appropriate for time series data (where approximate LFO cross validation is likely to perform better), the approximation used here to avoid refitting is likely to be poor, and we are not accounting for this by refitting the model as required.
Code
loos <- map(nowcasts, \(x) x$fit[[1]]$loo())
loo_compare(loos)
#> elpd_diff se_diff
#> Reference: Age, Report: Day of week 0.0 0.0
#> Reference: Age and week, Report: Day of week -0.9 5.7
#> Reference: Age and week by age, Report: Day of week -2.8 4.2
#> Reference: Fixed, Report: Day of week -86.9 11.4
#> Reference: Fixed, Report: Fixed -619.2 46.0We see that the most model which includes day of the week effects for the date of report substantially outperformed the baseline model with no adjustment and that the more complex models that adjusted for variation by age and week for the date of test improved estimated out of sample performance but uncertainty around these estimates was wide.
More rigorously, we can evaluate the nowcasts using proper scoring rules from the scoringutils package including the continuous ranked probability score.
Here we limit the nowcasts scored to the last 7 days of data to make interpretation easier, transform nowcasts into format required for scoringutils, link with the latest available data, and the finally call scoringutils::score().
Note that as we are only scoring a single nowcasts it is difficult to generalise our findings as this one day of reporting may have been unusual. To have a more informed view of which model to pick we would ideally nowcast a range of dates and evaluate each of them.
As a first step we score overall performance. Here we see that the baseline model with no variation actually performs very well with only models that include at least day of the week, age groups and variation by week performing comparably. Other performance characteristics are relatively similar across models (with all models being biased towards underprediction for example).
Code
eval_obs <- latest_nat_germany[reference_date > (max(reference_date) - 7)]
scores <- map_dfr(
nowcasts, as_forecast_sample, eval_obs, .id = "model"
) |>
rbind(
independent_nowcast |>
map_dfr(as_forecast_sample, eval_obs) |>
within({
model <- "Independent by age, Reference: Week, Report: Day of week"
}),
fill = TRUE
) |>
as.data.table() |>
within({
.group <- NULL
}) |>
as_forecast_sample() |>
score()
scores |>
summarise_scores(by = "model") |>
summarise_scores(fun = signif, digits = 2, by = "model") |>
kable()| model | bias | dss | crps | overprediction | underprediction | dispersion | log_score | mad | ae_median | se_mean |
|---|---|---|---|---|---|---|---|---|---|---|
| Reference: Fixed, Report: Fixed | -0.011 | 6.0 | 12.0 | 4.30 | 3.8 | 4.1 | 3.9 | 17 | 18 | 1300 |
| Reference: Fixed, Report: Day of week | -0.250 | 7.0 | 12.0 | 1.20 | 7.5 | 3.0 | 4.2 | 13 | 16 | 560 |
| Reference: Age, Report: Day of week | -0.390 | 6.8 | 9.9 | 0.68 | 6.3 | 2.9 | 4.0 | 12 | 13 | 400 |
| Reference: Age and week, Report: Day of week | 0.048 | 5.5 | 8.4 | 3.30 | 1.6 | 3.5 | 3.6 | 15 | 12 | 570 |
| Reference: Age and week by age, Report: Day of week | -0.200 | 5.7 | 8.4 | 1.80 | 3.1 | 3.5 | 3.7 | 15 | 12 | 430 |
| Independent by age, Reference: Week, Report: Day of week | -0.039 | 5.7 | 9.4 | 2.90 | 1.4 | 5.1 | 3.7 | 21 | 13 | 910 |
Finally we look across all scores relative to the simple model with no variation. This nicely captures the role of the last data point on performance but also highlights more variation across reference dates and age groups between models. The difference in performance between the hierarchical by age models and the model that treats age groups independently is also very clear.
Code
relative_scores <- scores |>
add_relative_skill(
by = c("reference_date", "age_group"),
baseline = "Reference: Fixed, Report: Fixed"
) |>
summarise_scores(by = c("model", "reference_date", "age_group"))
relative_scores <- relative_scores[!model == "Reference: Fixed, Report: Fixed"]
plot <- ggplot(relative_scores) +
aes(x = reference_date, y = crps_scaled_relative_skill, col = model) +
geom_hline(yintercept = 1, linetype = 2, linewidth = 1.2, alpha = 0.5) +
geom_line(linewidth = 1.1, alpha = 0.6) +
geom_point(size = 1.2) +
facet_wrap(vars(age_group)) +
scale_color_brewer(palette = "Dark2") +
scale_y_log10(labels = scales::percent)
plot <- enw_plot_theme(plot) +
labs(x = "Reference date",
y = "Weighted interval score (relative to Reference: Fixed, Report: Fixed model)") + # nolint
guides(col = guide_legend(title = "Model", ncol = 2))
plot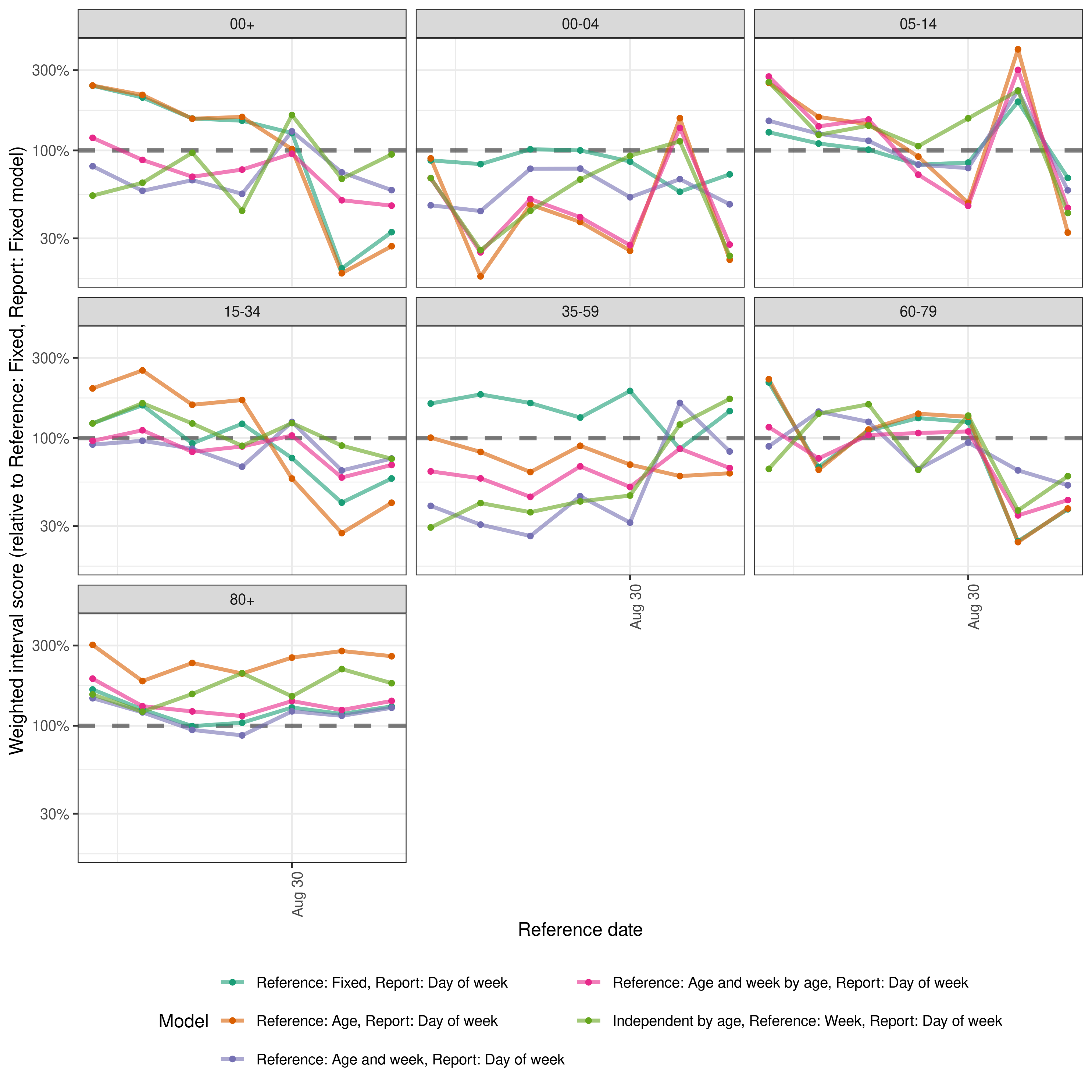
plot of chunk performance
Summary
In this vignette we showcased using epinowcast to nowcast age stratified COVID-19 hospitalisations in Germany by date of test with a series of increasingly complex models motivated by the data. We also showed some simple methods for exploring these nowcasts and evaluating them.
Using the limited information available to us (as we have only nowcast a single date and used performance for this date to motivate new models) it appears that all models performed acceptably and that, aside from the last data point, models with age and day of the week effects likely performed better. It is also fairly clear that performance degrades as the amount of reported data is reduced which intuitively makes sense with performance being particularly sensitive the first day reported data is available (i.e “now”). Our apparent finding that delays evolve fairly independently across age groups motivates choosing a model that is very flexible to this, at least for the date of reference model.
Despite the independent model and the fixed effect model both doing well overall, for most applications if choosing a model based on this evaluation, I would likely select a relatively flexible model (with day of the week, age group, and age stratified weekly variation) relying on the hierarchical structure to limit overfitting, and excepting a small reduction in performance in some edge cases (with the hope that these are edge cases and not a common feature of the data). However in practice, I would want to explore nowcasting and evaluating more dates and if possible a greater range of model structures (as discussed in the alternative modelling section of this vignette). Note that with the proper scoring approach taken here to understand model performance (and commonly used in the literature) we are ranking models based on absolute errors and so groups with high counts (such as the 35-59 age group) are more important to nowcast correctly than groups with smaller counts (such as those aged 80+).